
Making an API for Pitt
Published:
Making an API for Pitt
A journey into production code.
Note: This a post from 2015 copied from my Medium. Posted here on March 25, 2017.
The University of Pittsburgh is one of the largest universities in the United States. We have a brand new CS/Psychology/Business building (heavy sarcasm), state-of-the-art facilities (as in they’re literally art buildings), and no API to access simple data that students could use to build better tools.
On Thursday night, I set out to change that.
Starting Off — Courses
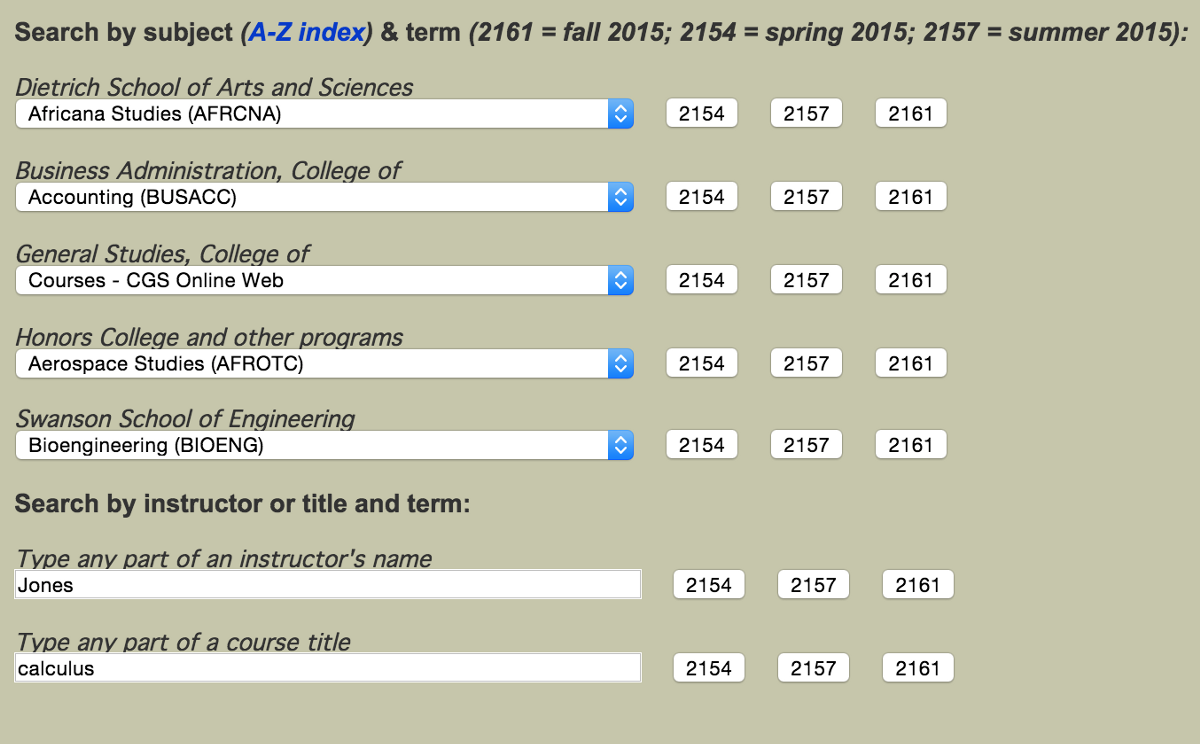
The first thing I wanted to do was have a way to programmatically access course information. This should be simple. Pitt has courses.as.pitt.edu, which is a website for students to access course descriptions.
Pitt’s websites are built with ASP.NET, which is weird. I really don’t like it.
Pressing on a button takes you to http://www.courses.as.pitt.edu/results-subj.asp. The search parameters have to be passed somewhere, so it’s time to check the Developer Console.
Bingo. The query parameters are SUBJ and TERM. Easy enough. Using urllib2 and BeautifulSoup (❤), the listings page can be scraped.
Computer Labs
Things get a lot more interesting here. Computer labs are something controlled entirely by CSSD, Pitt’s IT/Technical division. CSSD does not make any APIs available, but they have signs in their computer labs showing the availability of each one. Obviously, they have to get their data from somewhere.
You can check lab availability currently at http://technology.pitt.edu/service/lab-line-check-lab-availability.
Obviously this is dynamic data. There has to be a data source. So time to find it. Diving into the Developers Console, there isn’t actually much to see. CSS loading, JS loading, images, etc. However, an interesting call to simple_proxy.php is also made.
The url parameter is just a URL-encoded string that points to
http://www.ewi-ssl.pitt.edu/labstats_txtmsg/mdefault.aspx?labid=1&0=f&1=u&2=l&3=l&4=_&5=h&6=e&7=a&8=d&9=e&10=r&11=s&12==&13=1&14=&&15=f&16=u&17=l&18=l&19=_&20=s&21=t&22=a&23=t&24=u&25=s&26==&27=1.
Turns out anything after labstats_txtmsg isn’t necessary. Accessing http://www.ewi-ssl.pitt.edu/labstats_txtmsg/ gives you this:

Perfect. Some BeautifulSoup action later, I can now reliably provide computer lab status through the API.
Laundry Status
This was arguably the most fun and frustrating part to do.
Our laundry machines are controlled by Blackboard, and the ill-advertised UI to view the laundry machine status are controlled by a company called LaundryView. I had no idea about the UI until I went to https://m.pitt.edu/ and saw a place to view laundry status.
The UI itself is ugly and not mobile-responsive. That’s a shame, because most students use their phones for everything.
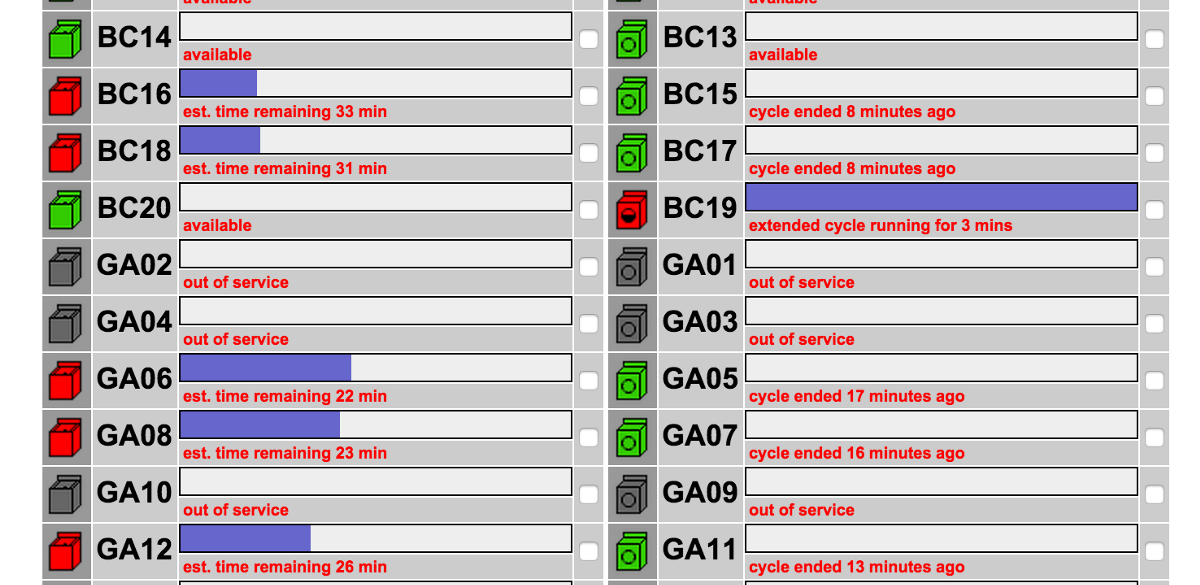
The URL for the above view is http://classic.laundryview.com/laundry_room.php?view=c&lr=2430136. If you click that link, nothing will pop up, but I’ll explain that later.
Looking at the Developer Console showed nothing interesting at first. I was not looking forward to scraping this monstrosity to get machine data. However, I noticed that this page refreshes every 60 seconds. Keeping the network tab open, I noticed two new calls being made every 60 seconds.

Gold. classic_laundry_room_ajax.php is just the same UI without styling. However, appliance_status_ajax.php gives this:
Awesome! Obviously not all the info I was looking for, but this is a URL that can be accessed without any authentication, so this was immediately tossed into a get_status_simple(self, loc) method with urllib2 and BeautifulSoup.
One thing to notice is that this is a classic view. Removing the classic part from the URL gives us a nicer UI! Still not mobile-responsive, and still not helpful.
This page makes two interesting calls immediately on load.

Dynamic room data! Gold! At this point I was very excited. This was the finish line. Turns out I was only halfway there. This is dynamicRoomData.php

At this point I thought of getting a degree in cryptography or something. However, keeping this open in one tab and the pretty UI in another, I started seeing some patters (over the course of an hour or two). 1:0:0:1: seemed to indicate a machine was free, and 1::0:0: seemed to indicate a machine was in use or out-of-service. Turns out this was a great guess, but a very naive one. Time to code it up!
Road block. Turns out urllib2 was not able to read the page. cURLing the page returned nothing. At this point I realized some authentication was being passed along to this page. After a lot of digging, I realized that I just needed to pass a cookie to the page to allow for access. I got my PHPSESSID, hardcoded it into get_status_detailed(), did the parsing and filtering, and went to sleep, fully realizing that tomorrow morning, that cookie would no longer be valid.
Tomorrow morning, the method didn’t work. Great, time to find a way to reliably get a valid PHPSESSID. After a lot of digging and looking at the Developer Console, I realized I could make an initial call to http://www.laundryview.com/laundry_room.php?view=c&lr=2430151, get the Set-Cookie header, and use that to make my API call. Bingo. Now we had a reliable way of getting this data.
Later on, as in yesterday, I realized that the whole string (1:60:1:37211:60:1:0:0:1:) had meaning. The first cluster is 1 or 0, 1 being free, 0 being in use. If the machine was in use, the second cluster stands for the amount of time left. However, if the seventh cluster doesn’t exist (::), that means that the machine is out-of-service. This was all coded into the current implementation of get_status_detailed() of the LaundryAPI.
Future Goals
I have some things I’m working on. My goals are to get a way to access the People directory at Pitt, as well as a way to get housing details (with MyPitt user authentication).
I also want to host the Python API on a web server so people can simply call an endpoint to get this data.
The Pitt API is available here: https://github.com/RitwikGupta/PittAPI
Disclaimer: This write up has skipped a lot of the dead-ends I faced for brevity.