LLMs, Autonomous Weapons, and AI Research

The views expressed are those of the author and do not reflect the official policy or position of the Department of War or the US Government.
In dramatic fashion, the United States Department of War (DoW) and Anthropic had an acrimonious, public breakup over the ability of the United States Government (USG) to utilize Anthropic’s models however it sees fit. The issue at hand is the use of Anthropic’s large language model, Claude, for mass domestic surveillance and autonomous weapons. The USG asserted that it will not be told what it can and cannot do with contracted capabilities; Anthropic maintained that some use cases are simply outside the bounds of what today’s technology can safely and reliably do, and that others are incompatible with democratic values regardless of capability. Simultaneously, on the same day the DoW designated Anthropic a supply chain risk, OpenAI signed a contract with the DoW for its own models. OpenAI’s position, articulated publicly by their head of national security partnerships Katrina Mulligan, is that their deal is meaningfully safer than Anthropic’s because it is structured around deployment architecture rather than contract language alone.
What is remarkable, and largely lost in the coverage, is that one of Anthropic’s two red lines is not novel. It is the current DoW policy. DoD Directive 3000.09, last updated in 2023 and sometimes called the Project Maven memo, requires that appropriate levels of human judgment be applied to autonomous weapons systems. Anthropic isn’t asking for anything the DoW hasn’t already agreed to on paper. My colleague Sarah Shoker, a former OpenAI geopolitics researcher who covered this dispute closely, makes this point well; please read her full essay for a richer treatment of the policy dimension than I’ll provide here.
So, what gives? Why is OpenAI okay with their models being deployed in these sensitive contexts while Anthropic is not? What are the actual needs of the U.S. Government, and what is the decision calculus for using new tools? Are LLMs even useful for autonomous weapons? And are AI researchers prepared to embrace the responsibility that their creations are now powerful instruments of war?
I’ve spent the last decade of my career studying the dual-use nature of AI in civilian and defense contexts. In this essay, I’ll break down how AI research has been repackaged as product, how that repackaging has produced mass confusion on both sides of this dispute, how autonomous weapons actually work and where LLMs fit—or, more precisely, don’t—within them, and why the researchers building these systems cannot keep treating the consequences as someone else’s problem.
Research as a Product
The United States Government grades how mature technology is through Technology Readiness Levels (TRL). Originally developed by NASA in the 1970s, TRL runs from 1 to 9. TRL 1 designates basic research such as math on a whiteboard, or a codebase on GitHub showing a model working on benchmarks. TRL 9, at the other end, designates systems that have been utilized and succeeded in operational settings.
The journey from TRL 1 to TRL 9 is hard, and it takes years. A new molten salt reactor concept may prove fruitful in the halls of Etcheverry Hall at Berkeley, but fielding it as a real product can take decades. There are well-documented “Valleys of Death” along the way. There is a massive gap in which TRL 3 applied research stalls before reaching TRL 7 low-rate initial production, and another gap before low-rate production scales to TRL 9 mass fielding. DoW program managers who work on early TRL maturation spend the majority of their time carefully grappling with the nuances of calling a technology a “success,” because fielding a technology has direct consequences on life. When a DoW program office enters into a production acquisition agreement with a large missile manufacturer, for example, both sides largely understand and certify the readiness of what is being acquired.
The modern AI industry did not emerge from the engineering culture of NASA or the DoW. It is not familiar with TRL. It is now routine for research that came out of a bullpen at Berkeley’s AI Research lab to ship as a consumer-facing product within months. This shift in culture is visible in the language of the industry itself. Major AI providers are now called “Something Labs,” implying to their researchers that they can continue doing Ph.D.-level work while being funded by billions in venture capital. TRL 2 or 3 ideas are shipped as TRL 6 or 7 products overnight, with ample marketing and press releases to certify their viability.
This gap is not obvious to the public, the government, or even the researchers themselves. When the government buys a product that is marketed and shipped as commercial-grade, they reasonably expect it to be significantly more mature than the AI industry asserts it actually is. When researchers ship code they know to be barely on the right side of done, they don’t expect it will be used for life-and-death decisions the following day. It is not shocking, then, that frontier AI companies and the USG are talking past one another. AI companies market models that are reshaping society; the USG takes this at face value and expects to use them as reliably and freely as they would a missile.
This dynamic is further muddied when AI companies have partnerships with third parties who integrate AI capabilities into the DoW, but then the same companies fight the DoW about those very use cases. DoW program managers believe their eyes. How can a company disagree with a use case that their own partner is demonstrating?
There is also a harder structural point here. Frontier AI companies are incentivized to appear TRL-ready; that’s what closes enterprise contracts and drives valuations. The DoW is incentivized to appear to be acquiring mature technology; deploying something that is ultimately low TRL research unnecessarily risks lives and invites Congressional scrutiny. Both sides have structural reasons to paper over the maturity gap. That the gap exists at all is, at this point, an open secret that neither side has any particular interest in advertising.
The Function and Limitations of Autonomous Weapons
Autonomous weapons are one of the big sticking points of the Anthropic/DoW rift. Anthropic maintains that it cannot agree to its LLM being used for fully autonomous weapons. It is correct, but not for the reasons the press coverage implies. LLMs are still autonomously mass-deleting sensitive data despite being told not to. They hallucinate. They are categorically unreliable in the ways that matter most in lethal decision-making. Researchers at frontier AI companies are not building products for these use cases, which means they are not in any position to certify them for those uses either.
What frontier AI companies largely elide in their public statements is that LLMs are almost certainly never going to be used in the kinetic phase of a weapons engagement anyway. They are technically the wrong model for the job!
An autonomous weapon can be understood as five integrated components: flight hardware, payload, compute, networking, and power. The design of modern autonomous weapons prioritizes payload capacity and range, which means making the most of limited power generation and minimizing weight. This results in highly constrained onboard compute, often orders of magnitude smaller than what LLMs require. The power draw of Transformer-based language models alone is prohibitive, producing an unacceptable reduction in range before even getting to the problems associated with latency.
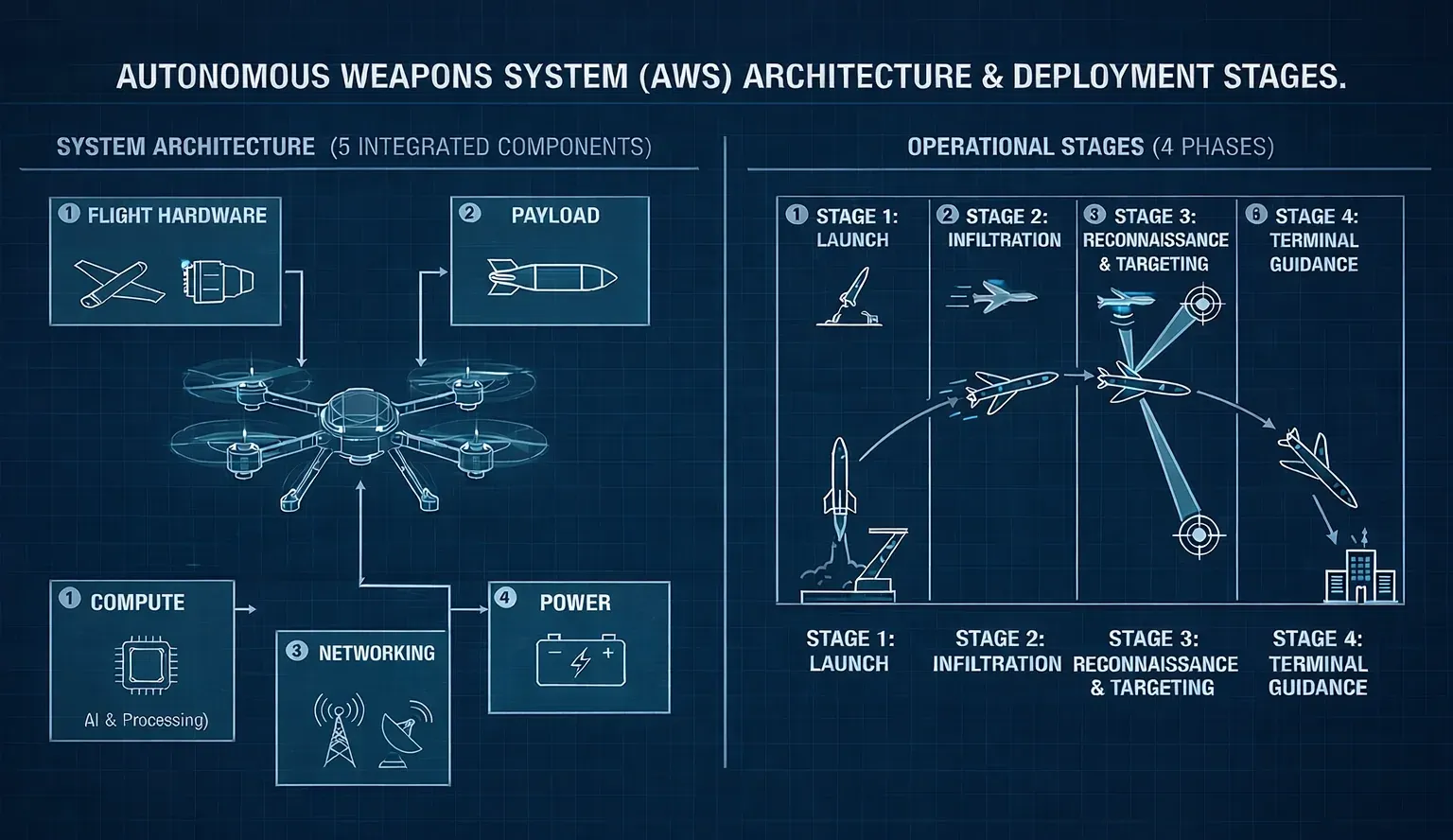
There are four stages in which autonomous weapons operate: launch, infiltration, reconnaissance and targeting, and terminal guidance. I’ll set aside target curation and battle damage assessment, both crucial and legally mandated stages to the left and right of the autonomous weapon, for now, though I’ll return to them briefly.
The launch phase is largely devoid of AI. An autonomous weapon leaves its launcher, gains signal to its command node, and begins flight.
The infiltration phase is the longest, and it’s where AI has found the most traction. The weapon has to fly from its launch point to its target over a range that has grown from single kilometers to hundreds. Along that path, it has to avoid counter-weapons systems and maintain course against increasing sensor and communications jamming. Computer vision systems which provide geography-based location fixes have proved to be useful here.
Once near its target after a long and usually imprecise infiltration, the weapon begins to search for the actual aim point. This can be achieved using GPS coordinates after a reliable navigation fix, or AI-enabled object recognition to identify a specific target.
Finally, in the terminal phase, the weapon gains speed towards the target and must perform high-speed maneuvers to correct for its own instability, sensor degradation, and any potential target movement.
LLMs have shown the most theoretical promise during infiltration under ideal conditions. But we’ve already established that LLMs cannot run onboard the weapons system. That implies the weapon has reliable network connectivity to remote servers where an LLM can be queried. Maybe an LLM could help coordinate multiple drones, or process data streams to generate updated routes. The problem is that the velocity of weapons systems is fundamentally incompatible with the latency of networked LLM inference. Any response would be outdated by the time it arrived. In less-than-ideal conditions, communications may not reach a server at all.
LLMs are also, in a meaningful technical sense, blind. When provided images or video frames, they largely ignore the visual data and hallucinate based on the text prompt instead. This is not acceptable in a battlefield environment. And even if that limitation were resolved, the best computer vision systems—which already substantially outperform LLMs on vision tasks—still struggle with degraded or uncommon inputs like smoke, thermal imagery, or sensor noise. The environment where autonomous weapons operate is specifically the environment where AI systems perform worst.
The Cloud Safeguard Doesn’t Hold
Mulligan’s public defense of the OpenAI contract is worth engaging seriously, because it is a serious argument. Her central claim is that deployment architecture matters more than contract language: by limiting OpenAI’s deployment to a cloud API, models cannot be integrated directly into weapons systems, sensors, or operational hardware. It is a genuine architectural constraint. If a model can only be reached via a cloud endpoint, there are meaningful limits on how tightly it can be embedded into a weapons system operating in the field.
The problem is that this argument describes today’s deployment architecture, not tomorrow’s.
The DoW has invested heavily for years in what it calls the “tactical edge”: programs designed to forward-deploy compute nodes into denied, degraded, intermittent, and limited-bandwidth (DDIL) environments. A tactical edge node is, functionally, a cloud node that travels with the force. When a model is pushed to a tactical edge node, it is no longer “in the cloud” in any operationally meaningful sense. LLMs are known to perform significantly worse when deployed on constrained hardware. Further, OpenAI does not own and operate the tactical edge. How can they guarantee that the safeguards they have on their infrastructure holds in a deployed environment? The physical and network separation that makes OpenAI’s architectural safeguard work is not perfectly coherent.
OpenAI is making a commitment about the present. The DoW’s tactical edge investment is a commitment about the future. These two facts are in direct tension, and neither company’s reported contract language resolves that tension.
One more note on the bracketed stages: target curation and battle damage assessment, which I set aside for the purposes of tracing the kinetic phase. Real and present AI risks live here as well. These are higher-latency, analysis-heavy tasks where LLMs are far more plausibly useful and where the human-in-the-loop question is far murkier. That deserves its own treatment, and I do not want the narrowness of this essay’s focus on the kinetic phase to imply the broader risk picture is benign.
The Responsibilities of AI Researchers
There is no better feeling than building something highly coveted and used by millions of people. For academics especially, whose entire careers are measured in citations, having their work embraced by the world is unparalleled. But AI researchers have to understand that their work is no longer conducted in isolation. Every equation derived, every line of code written, when amplified by multi-billion dollar companies, carries with it the risk of uses you never planned for.
San Francisco AI circles spend a lot of time on existential risks. These are, in many ways, the intellectually seductive norm. They are squishy, easy to debate, and a “future” problem. The present risks are harder. The technology we build exacerbates real harms every day, and those harms don’t have clean technical solutions. They require technologists to engage with the societal structures their work is reshaping not just as critics, but as participants.
We are not well-prepared for this. Engineers around the United States are required to take an ethics course (or two) before they graduate. Most computer scientists take exactly zero. Many AI scientists never encounter policy or international relations curricula despite themselves being the current geopolitical hot topic.
Here is the more uncomfortable point: AI researchers tend to treat the government as some external entity, something to be observed and criticized from the outside. But that framing is wrong. Abraham Lincoln said, at Gettysburg, that this government is of the people, by the people, and for the people. If you’ve embraced the United States as home, as I have, this is a description of what you are part of. The government is not the other. It is us—including you, the researcher shipping models that will be integrated into its systems, its decisions, and its conflicts. The responsibility that comes with that is not dischargeable by publishing a paper, writing a statement, or building a product with a terms-of-service clause.
The government is already strapped for talent. You may hold a legitimate position against specific uses of your technology, and that position may be correct. The government deserves vocal criticism. But, it is even more deserving of your effort to fix the misalignment, to help it understand what your tools actually are, what they can actually do, and where the real risks actually live. Sitting in a corner and building things, then issuing a press release when those things are misused, is not a substitute for being in the room. As Theodore Roosevelt said, “it is not the critic who counts… the credit belongs to the man who is actually in the arena.”
Conclusion
The DoW has simultaneously designated Anthropic a supply chain risk and threatened to invoke the Defense Production Act to compel their participation. These two positions are incompatible. One says Anthropic is a threat. The other says Claude is indispensable. That contradiction has emerged from two institutions operating in near-total isolation from each other, each having internalized a version of the technology that the other would not recognize. The DoW sees a weapons-grade capability with the potential to shape the world. Anthropic sees in-progress research that requires significant guardrails.
That gap does not close by itself. It does not close through press releases, contract negotiations, or Congressional hearings. It closes when the people who actually understand what these systems are, and are not, decide that the outcome is their problem too. The decisions will be made regardless. The only question is whether anyone in the room understood what they were deciding.
Errata
- March 3, 2026: I initially stated that low-rate initial production was TRL 6. This was a typo. LRIP is TRL 7.